Oculus Rift PC SDK from version 0.5 to 0.7
2015-10-25 23:46:43
Oculus PC SDK API has been stable for about a year but the late august 2015 v0.7 has seen introduction of a major architecture shift.
Always eager to lower latency, the new architecture, used with the latest VR mode drivers from GPU maker AMD and NVIDIA should bring performance to another level.
In daily use I've already seen a huge improvement : FINALLY we are able to get the VR directly into the headset, and at the same time, have the rendering mirrored on the main screen.
Before it was almost mandatory to have the DK2 device set as the primary monitor which was awful when trying to launch something from the desktop as everything is barely readable split in half for each eye and with only the center zone being sharp.
Alas ! The DK2 is no longer seen as a monitor but light's up immediately when an Oculus ready application is started.
From the programming side the shift is also substantial while the motion tracking interface remain unchanged, the graphical rendering interface has seen big changes
at the beginning of a new frame and
to indicate the end of a frame and the buffer swap, are no longer relevant.
It all starts with a new initialisation method :
This method return a "TextureSet" : an array of OpenGL allocated textures.
One has to bind a framebuffer to the texture, I have managed to reuse my FrameBuffer class by allowing it to receive an already allocated texture as backing texture for a newly created framebuffer.
At the end of all frame draw calls, one has to call the following method :
The main paramater is an ovrLayerHeader which is composed of :
So for each eye, one has to bind our textureSet to "ld.ColorTexture[eye]".
Personnally I didn't saw the point of having a different texture for each eye, so I only use one textureSet that contains half of the surface for each eye.
Then we blit mirror texture to back buffer, I guess this is buffer that support the final rendering.
Note that SDL_GL_SwapWindow is back and that we have to call it manually.
And this this is were the magic happens :
First we have to manully increase the index on our textureset so that the next texture will be used for the rendering on the next ovr_SubmitFrame.
We have to do so because the texture used in ovr_SubmitFrame CANNOT be used in the next call to ovr_SubmitFrame. I know it because binding the backed framebuffer immediately after having called ovr_SubmitFrame will cause an error.
This is why, I am swapping between 2 Frambuffers, each one is bound to one texture of my textureset structure. I might just have been lucky but ovr_CreateSwapTextureSetGL for my part only returns a set of 2 textures.
Always eager to lower latency, the new architecture, used with the latest VR mode drivers from GPU maker AMD and NVIDIA should bring performance to another level.
In daily use I've already seen a huge improvement : FINALLY we are able to get the VR directly into the headset, and at the same time, have the rendering mirrored on the main screen.
Before it was almost mandatory to have the DK2 device set as the primary monitor which was awful when trying to launch something from the desktop as everything is barely readable split in half for each eye and with only the center zone being sharp.
Alas ! The DK2 is no longer seen as a monitor but light's up immediately when an Oculus ready application is started.
From the programming side the shift is also substantial while the motion tracking interface remain unchanged, the graphical rendering interface has seen big changes
ovrHmd_BeginFrame(hmd, 0);
at the beginning of a new frame and
ovrHmd_EndFrame(hmd, headPose, &fb_ovr_tex[0].Texture);
to indicate the end of a frame and the buffer swap, are no longer relevant.
It all starts with a new initialisation method :
ovrResult result2 = ovr_CreateSwapTextureSetGL(hmd,GL_RGBA, this->screenWidth, this->screenHeight, &textureSet);
if(!OVR_SUCCESS(result2)){
puts("ovr_CreateSwapTextureSetGL ERROR");
exit(0);
}
This method return a "TextureSet" : an array of OpenGL allocated textures.
One has to bind a framebuffer to the texture, I have managed to reuse my FrameBuffer class by allowing it to receive an already allocated texture as backing texture for a newly created framebuffer.
At the end of all frame draw calls, one has to call the following method :
ovrResult result = ovr_SubmitFrame(hmd, 0, NULL,&layers, 1);
if (!OVR_SUCCESS(result)) {
puts("ovr_SubmitFrame ERROR");
exit(0);
}
The main paramater is an ovrLayerHeader which is composed of :
ld.ColorTexture[eye] = textureSet;
ld.Viewport[eye] = viewPort;
ld.Fov[eye] = hmdDesc.DefaultEyeFov[eye];
ld.RenderPose[eye] = headPose[eye];
So for each eye, one has to bind our textureSet to "ld.ColorTexture[eye]".
Personnally I didn't saw the point of having a different texture for each eye, so I only use one textureSet that contains half of the surface for each eye.
Then we blit mirror texture to back buffer, I guess this is buffer that support the final rendering.
glBindFramebuffer(GL_READ_FRAMEBUFFER, mirrorFBO);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
GLint w = ((ovrGLTexture*)mirrorTexture)->OGL.Header.TextureSize.w;
GLint h = ((ovrGLTexture*)mirrorTexture)->OGL.Header.TextureSize.h;
glBlitFramebuffer(0, h, w, 0,
0, 0, w, h,
GL_COLOR_BUFFER_BIT, GL_NEAREST);
glBindFramebuffer(GL_READ_FRAMEBUFFER, 0);
SDL_GL_SwapWindow(displayWindow);
Note that SDL_GL_SwapWindow is back and that we have to call it manually.
And this this is were the magic happens :
textureSet->CurrentIndex = (textureSet->CurrentIndex + 1) % textureSet->TextureCount;
swapFBdrawing(&this->fbDrawing, &this->fbDrawing2);
First we have to manully increase the index on our textureset so that the next texture will be used for the rendering on the next ovr_SubmitFrame.
We have to do so because the texture used in ovr_SubmitFrame CANNOT be used in the next call to ovr_SubmitFrame. I know it because binding the backed framebuffer immediately after having called ovr_SubmitFrame will cause an error.
This is why, I am swapping between 2 Frambuffers, each one is bound to one texture of my textureset structure. I might just have been lucky but ovr_CreateSwapTextureSetGL for my part only returns a set of 2 textures.
Source translation with Emscripten
2015-10-12 22:10:00
Emscripten is a software that allows to transform C/C++ code to Javascript, achieving near native speed.
Since I still do a lot of my personal work in C/C++, the idea of being able to push my work directly to the web sounded so sweet that I had to give it a try.
1. Download
http://kripken.github.io/emscripten-site/docs/getting_started/downloads.html
I'm running Windows 7 and the latest web installer seems broken for me (emsdk-1.34.1-web-64bit.exe)
I had better results with the offline installer as it worked flawlessly.
2. Usage
For a single source file its pretty straightforward :
The default output is a a.out.js file containing the translated source code.
First impression : this is huge.
Even converting a one liner, with the -o2 option (that "minify" and optimize the JS), the generated source is 300kb !
Then one can understand what really is Emscripten : Emscripten produces a javascript implementation of the source code with a javascript virtual machine on which the generated source will run.
No I won't translate my superfast sorting algorithm into a directly pluggable javascript equivalent.
A function can be exported to javascript using the proper export directive.
After having copy-pasted the 300kb source in your html source, calling the generated code is easy from Javascript :
int_sqrt : method name
'number' : return type (or null if void)
['number'] : list of parameters
Easy ? Because you didn't use pointer.
For Emscripten, pointers are number referencing memory location inside the javascript virtual machine.
Which means that memory has to be allocated and data copied there before calling the target method.
Here is the method I was willing to port to Javascript:
Feeding the good values to the function was painful !
3. Conclusion
Porting C/C++ the code has proven a viable solution, especially knowing that commercial games were ported to web-browser using this technique.3D draw calls are even map to their WebGL equivalent.
But, it's not a lightweight solution, a 300kb minimal runtime is huge.
The biggest put-off is probably the difficulty to input/ouput non-primitive types. Data exchange between Javascript and C/C++ is not very smooth a require hand-crafted and error-prone operations.
Since I still do a lot of my personal work in C/C++, the idea of being able to push my work directly to the web sounded so sweet that I had to give it a try.
1. Download
http://kripken.github.io/emscripten-site/docs/getting_started/downloads.html
I'm running Windows 7 and the latest web installer seems broken for me (emsdk-1.34.1-web-64bit.exe)
I had better results with the offline installer as it worked flawlessly.
2. Usage
For a single source file its pretty straightforward :
emcc source.c
The default output is a a.out.js file containing the translated source code.
First impression : this is huge.
Even converting a one liner, with the -o2 option (that "minify" and optimize the JS), the generated source is 300kb !
Then one can understand what really is Emscripten : Emscripten produces a javascript implementation of the source code with a javascript virtual machine on which the generated source will run.
No I won't translate my superfast sorting algorithm into a directly pluggable javascript equivalent.
A function can be exported to javascript using the proper export directive.
#include <math.h>
extern "C" {
int int_sqrt(int x) {
return sqrt(x);
}
}
After having copy-pasted the 300kb source in your html source, calling the generated code is easy from Javascript :
int_sqrt = Module.cwrap('int_sqrt', 'number', ['number'])
int_sqrt(12)
int_sqrt(28)
int_sqrt : method name
'number' : return type (or null if void)
['number'] : list of parameters
Easy ? Because you didn't use pointer.
For Emscripten, pointers are number referencing memory location inside the javascript virtual machine.
Which means that memory has to be allocated and data copied there before calling the target method.
Here is the method I was willing to port to Javascript:
extern "C" {
int computeMove(int playerValue, int x, int y,char * tab,int p_x,int p_y, int * opponentPos, int opponentCount,int *newx, int *newy) {
...
}
Feeding the good values to the function was painful !
c_computeMove = Module.cwrap('computeMove', 'number',['number' , 'number' , 'number', 'number', 'number' , 'number' , 'number' , 'number' , 'number' , 'number'])
//int playerValue;
var playerValue = -1;
//int x;
var x = 0;
//int y;
var y = 0;
//char * tab;
var tab = new Array();
tab.push(-1)
for (var i = 1;i < 700;i++) { tab.push(0);}
var tab_data = new Int8Array(tab);
var tab_nDataBytes = tab_data.length * tab_data.BYTES_PER_ELEMENT;
var tab_dataPtr = Module._malloc(tab_nDataBytes);
var tab_dataHeap = new Uint8Array(Module.HEAPU8.buffer, tab_dataPtr, tab_nDataBytes);
tab_dataHeap.set(new Uint8Array(tab_data.buffer));
//int p_x;
var p_x = 0;
//int p_y;
var p_y = 0;
//int * opponentPos;
var data = new Int32Array([player_x, player_y]);
var nDataBytes = data.length * data.BYTES_PER_ELEMENT;
var dataPtr = Module._malloc(nDataBytes);
var dataHeap = new Uint8Array(Module.HEAPU8.buffer, dataPtr, nDataBytes);
dataHeap.set(new Uint8Array(data.buffer));
//int opponentCount;
var opponentCount = 1;
//int *newx;
var newx = new Array();
for (var i = 0;i < 1;i++) { newx.push(-1);}
var newx_data = new Int32Array(newx);
var newx_nDataBytes = newx_data.length * newx_data.BYTES_PER_ELEMENT;
var newx_dataPtr = Module._malloc(newx_nDataBytes);
var newx_dataHeap = new Uint8Array(Module.HEAPU8.buffer, newx_dataPtr, newx_nDataBytes);
newx_dataHeap.set(new Uint8Array(newx_data.buffer));
//int *newy;
var newy = new Array();
for (var i = 0;i < 1;i++) { newy.push(-1);}
var newy_data = new Int32Array(newy);
var newy_nDataBytes = newy_data.length * newy_data.BYTES_PER_ELEMENT;
var newy_dataPtr = Module._malloc(newy_nDataBytes);
var newy_dataHeap = new Uint8Array(Module.HEAPU8.buffer, newy_dataPtr, newy_nDataBytes);
newy_dataHeap.set(new Uint8Array(newy_data.buffer));
3. Conclusion
Porting C/C++ the code has proven a viable solution, especially knowing that commercial games were ported to web-browser using this technique.3D draw calls are even map to their WebGL equivalent.
But, it's not a lightweight solution, a 300kb minimal runtime is huge.
The biggest put-off is probably the difficulty to input/ouput non-primitive types. Data exchange between Javascript and C/C++ is not very smooth a require hand-crafted and error-prone operations.
Functional thinking paradigm over syntax
2015-09-17 15:51:07
As newcomer in the world of functional programming, I have been through this interesting book to start my journey :

I like the fact that it tries to sum up the concepts of functional programming and map them to an imperative programming language, Java for that matters. For sure programmers from another background may not find this approach as meaningful.
This book is also language agnostic with functional examples in Groovy, Scala, Closure which give a good overiew of the different syntaxes and implementations.
Functional programming has been around for a long time now with even in the Java world, for instance, the Scala language making functional programming its selling point.
Now even Java 8 introduce some bits of functional programming with the so called "Lambda blocks".
In short, functional programming is a programming style where functions are considered as variables.
In imperative programming, a succession of instructions executed in sequential order modify a context.
Functional programming the same result would be achieved through successive function calls.
Moreover, functional programming allows for new design patterns and new software paradigms.
Closures : function passed as argument of a method which have access to their declaration context.
Laziness : Delaying evaluation of an expression until needed, one defining aspect of functional programming.
Dataset stream : Finite or infinite list of objects where one can apply high order functions. High order function are daisy-chained and thanks to laziness, evalution is done only on a terminal function, a function requiring an immediate result.
Thanks to generalized immuatability and higher level of abstraction, functional programming favours parallel optmization at runtime level.
Operators on streams :
- Map() apply an operation to each element of a stream creating a new stream.
- Filter() filters a stream with a predicate function returning the filtered stream.
- Reduce() apply an operation to a stream and returning a result.
Curry and partials : Design pattern that creates functions that returns the same function with less arity.
Memoization : Design pattern where caching is done implicitly by creating a function that wraps the memoized function and a caching mecanism.
Why is there a tight bond between immutability and functional programming ?
The paradigm shift of functional programming means that the objects no longer carry the application logic. "Moving parts" now are functions.
In functional programming, the logic should be wrap around "pure functions" which means functions that return the same result for a given input, this can only be enforced by using immutable objects as arguments. For instance : passing a stateful "context" as argument of a function breaks the functional programmiong paradigm.
The side effect of immutability is that it greatly eases parallel execution as it clearly separates independant execution units.
In the same idea, laziness can only be achieved knowning that an input parameter will not be changed during execution, hence immutability.
I like the fact that it tries to sum up the concepts of functional programming and map them to an imperative programming language, Java for that matters. For sure programmers from another background may not find this approach as meaningful.
This book is also language agnostic with functional examples in Groovy, Scala, Closure which give a good overiew of the different syntaxes and implementations.
Functional programming has been around for a long time now with even in the Java world, for instance, the Scala language making functional programming its selling point.
Now even Java 8 introduce some bits of functional programming with the so called "Lambda blocks".
In short, functional programming is a programming style where functions are considered as variables.
In imperative programming, a succession of instructions executed in sequential order modify a context.
Functional programming the same result would be achieved through successive function calls.
Moreover, functional programming allows for new design patterns and new software paradigms.
Closures : function passed as argument of a method which have access to their declaration context.
Laziness : Delaying evaluation of an expression until needed, one defining aspect of functional programming.
Dataset stream : Finite or infinite list of objects where one can apply high order functions. High order function are daisy-chained and thanks to laziness, evalution is done only on a terminal function, a function requiring an immediate result.
Thanks to generalized immuatability and higher level of abstraction, functional programming favours parallel optmization at runtime level.
Operators on streams :
- Map() apply an operation to each element of a stream creating a new stream.
- Filter() filters a stream with a predicate function returning the filtered stream.
- Reduce() apply an operation to a stream and returning a result.
Curry and partials : Design pattern that creates functions that returns the same function with less arity.
Memoization : Design pattern where caching is done implicitly by creating a function that wraps the memoized function and a caching mecanism.
Why is there a tight bond between immutability and functional programming ?
The paradigm shift of functional programming means that the objects no longer carry the application logic. "Moving parts" now are functions.
In functional programming, the logic should be wrap around "pure functions" which means functions that return the same result for a given input, this can only be enforced by using immutable objects as arguments. For instance : passing a stateful "context" as argument of a function breaks the functional programmiong paradigm.
The side effect of immutability is that it greatly eases parallel execution as it clearly separates independant execution units.
In the same idea, laziness can only be achieved knowning that an input parameter will not be changed during execution, hence immutability.
1) You have thread T1, T2 and T3, how will you ensure that thread T2 run after T1 and thread T3 run after T2?
2015-08-28 10:12:36
Let's remember the basics of Java threading :
The code that has to be run in a different thread than the main execution can be written in a class that implements Runnable :
Then a thread object will be declared with the "Runnable" object as a parameter.
Another way of implementing threads is to extend the "Thread" class:
Then instanciate the extended class and call the start method:
I use to consider both technique as being equivalent, implementing Runnable is less restrictive as it's only possible to extend one class but multiple interfaces can be implemented.
Starting from Java 1.5, a new framework that eases implementation of worker thread pool is available : the java.util.concurrent.
Here I have set a number of thread to 10, then my runnable object will automatically be dispatched on any available thread.
Using thread pool saves thread creation overhead, and allows to control the number of thread running concurrently.
Obviously, Thread class cannot be extended anymore when using the Executor framework.
Bringing back to the main question : You have thread T1, T2 and T3, how will you ensure that thread T2 run after T1 and thread T3 run after T2?
If you are allowed to synchronize start call within the main thread, you can call the Thread.join() method after each Thread.start() to wait for thread execution.
IF your threads extends Thread, you can pass previously create Thread object and call the Thread.join() method on the thread that has to wait.
No matter in which order mt1.start(), mt2.start() and mt3.start() are called, inevitably the execution result will always be :
Now let say that you want to use runnable implementation and you want to synchronize runnable within run code.
You do not know in advance on which thread it will run. Well you could pass the thread running the Runnable object as a parameter, but you cannot do that while using thread pool.
One has to use the wait() and notifiy() :
when calling wait() on any java Object, the running object will stop its execution until a thread calls notify() on the same object.
Thus by making Runnable r2 wait() on r1, and r1 notifiy on itself when it has ended, we can make r2 wait for r1 execution.
NOTE that the wait() releases the lock that is acquired by the previously called synchronized(), this might be counterintuitive.
BUT if r1 calls notify on itself before r2 calls r1.wait(), r2 will never resume its execution.
To Counter this problem, I added a "ended" flag, so that whenever r1 finishies, it set this flag to "true" so that r2 won't call wait() if r1 has already finished its execution.
The code that has to be run in a different thread than the main execution can be written in a class that implements Runnable :
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Run");
}
}
Then a thread object will be declared with the "Runnable" object as a parameter.
Another way of implementing threads is to extend the "Thread" class:
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("Run");
}
}
Then instanciate the extended class and call the start method:
public static void main(String[] argv) {
MyThread mt = new MyThread();
mt.start();
}
I use to consider both technique as being equivalent, implementing Runnable is less restrictive as it's only possible to extend one class but multiple interfaces can be implemented.
Starting from Java 1.5, a new framework that eases implementation of worker thread pool is available : the java.util.concurrent.
public static void main(String[] argv) {
java.util.concurrent.ExecutorService executor = java.util.concurrent.Executors.newFixedThreadPool(10);
for (int i = 0; i < 500; i++) {
Runnable worker = new MyRunnable();
executor.execute(worker);
}
executor.shutdown();
}
Here I have set a number of thread to 10, then my runnable object will automatically be dispatched on any available thread.
Using thread pool saves thread creation overhead, and allows to control the number of thread running concurrently.
Obviously, Thread class cannot be extended anymore when using the Executor framework.
Bringing back to the main question : You have thread T1, T2 and T3, how will you ensure that thread T2 run after T1 and thread T3 run after T2?
If you are allowed to synchronize start call within the main thread, you can call the Thread.join() method after each Thread.start() to wait for thread execution.
public static class MyRunnable implements Runnable {
int id;
public MyRunnable(int id) {
this.id = id;
}
@Override
public void run() {
System.out.println("Th"+id+"Run");
}
}
public static void main(String[] argv) throws InterruptedException {
Thread t1 = new Thread(new MyRunnable(1));
Thread t2 = new Thread(new MyRunnable(2));
Thread t3 = new Thread(new MyRunnable(3));
t1.start();
t1.join();
t2.start();
t2.join();
t3.start();
t3.join();
}
IF your threads extends Thread, you can pass previously create Thread object and call the Thread.join() method on the thread that has to wait.
public static class MyThread extends Thread {
private Thread threadToWait = null;
public MyThread(Thread ttw, int id) {
threadToWait = ttw;
this.setName("Th"+id);
}
@Override
public void run() {
if (threadToWait != null) {
try {
threadToWait.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(this.getName() + "Run");
}
}
public static void main(String[] argv) {
MyThread mt1 = new MyThread(null,1);
MyThread mt2 = new MyThread(mt1,2);
MyThread mt3 = new MyThread(mt2,3);
mt3.start();
mt2.start();
mt1.start();
}
No matter in which order mt1.start(), mt2.start() and mt3.start() are called, inevitably the execution result will always be :
Th1Run
Th2Run
Th3Run
Now let say that you want to use runnable implementation and you want to synchronize runnable within run code.
You do not know in advance on which thread it will run. Well you could pass the thread running the Runnable object as a parameter, but you cannot do that while using thread pool.
One has to use the wait() and notifiy() :
when calling wait() on any java Object, the running object will stop its execution until a thread calls notify() on the same object.
Thus by making Runnable r2 wait() on r1, and r1 notifiy on itself when it has ended, we can make r2 wait for r1 execution.
NOTE that the wait() releases the lock that is acquired by the previously called synchronized(), this might be counterintuitive.
BUT if r1 calls notify on itself before r2 calls r1.wait(), r2 will never resume its execution.
To Counter this problem, I added a "ended" flag, so that whenever r1 finishies, it set this flag to "true" so that r2 won't call wait() if r1 has already finished its execution.
public static class MyRunnable implements Runnable {
int id;
MyRunnable runnableToWait = null;
public volatile boolean ended = false;
public MyRunnable(int id,MyRunnable runnableToWait) {
this.id = id;
this.runnableToWait = runnableToWait;
}
@Override
public void run() {
if (runnableToWait != null) {
synchronized (runnableToWait) {
try {
if (!runnableToWait.ended) {
runnableToWait.wait();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Th"+id+"Run");
}
synchronized (this) {
this.notify();
}
} else {
synchronized (this) {
System.out.println("Th"+id+"Run");
this.notify();
this.ended = true;
}
}
}
}
public static void main(String argv[]) throws InterruptedException {
MyRunnable r1 = new MyRunnable(1,null);
MyRunnable r2 = new MyRunnable(2,r1);
MyRunnable r3 = new MyRunnable(3,r2);
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r2);
Thread t3 = new Thread(r3);
t3.start();
t2.start();
t1.start();
}
Java interview questions round-up
2015-08-27 11:28:47
I've gathered few java questions from differents website, so I will answer them whenever I'm in the mood, I also will add questions coming from my personal experience.
1) You have thread T1, T2 and T3, how will you ensure that thread T2 run after T1 and thread T3 run after T2?
2) What is the advantage of new Lock interface over synchronized block in Java? You need to implement a high performance cache which allows multiple reader but single writer to keep the integrity how will you implement it?
3) What are differences between wait and sleep method in java?
4) Write code to implement blocking queue in Java?
5) Write code to solve the Produce consumer problem in Java?
6) Write a program which will result in deadlock? How will you fix deadlock in Java?
7) What is atomic operation? What are atomic operations in Java?
8) What is volatile keyword in Java? How to use it? How is it different from synchronized method in Java?
9) What is race condition? How will you find and solve race condition?
10) How will you take thread dump in Java? How will you analyze Thread dump?
11) Why we call start() method which in turns calls run() method, why not we directly call run() method ?
12) How will you awake a blocked thread in java?
13) What is difference between CyclicBarriar and CountdownLatch in Java ?
14) What is immutable object? How does it help on writing concurrent application?
15) What are some common problems you have faced in multi-threading environment? How did you resolve it?
16) Difference between green thread and native thread in Java?
17) Difference between thread and process?
18) What is context switching in multi-threading?
19) Difference between deadlock and livelock, deadlock and starvation?
20) What thread-scheduling algorithm is used in Java?
21) What is thread-scheduler in Java?
22) How do you handle un-handled exception in thread?
23) What is thread-group, why its advised not to use thread-group in Java?
24) Why Executor framework is better than creating and managing thread by application ?
25) Difference between Executor and Executors in Java?
26) How to find which thread is taking maximum cpu in windows and Linux server?
27) difference between final, finally and finalize in Java?
28) how do you design another programming language which can run like Java?
29) when to use abstract class over interface in Java?
30) how does lambda expression of Java 8 was implemented?
31) how does generics in Java implemented internally?
32) What is apect oriented programming and describe the way it is used in the Spring framework.
1) You have thread T1, T2 and T3, how will you ensure that thread T2 run after T1 and thread T3 run after T2?
2) What is the advantage of new Lock interface over synchronized block in Java? You need to implement a high performance cache which allows multiple reader but single writer to keep the integrity how will you implement it?
3) What are differences between wait and sleep method in java?
4) Write code to implement blocking queue in Java?
5) Write code to solve the Produce consumer problem in Java?
6) Write a program which will result in deadlock? How will you fix deadlock in Java?
7) What is atomic operation? What are atomic operations in Java?
8) What is volatile keyword in Java? How to use it? How is it different from synchronized method in Java?
9) What is race condition? How will you find and solve race condition?
10) How will you take thread dump in Java? How will you analyze Thread dump?
11) Why we call start() method which in turns calls run() method, why not we directly call run() method ?
12) How will you awake a blocked thread in java?
13) What is difference between CyclicBarriar and CountdownLatch in Java ?
14) What is immutable object? How does it help on writing concurrent application?
15) What are some common problems you have faced in multi-threading environment? How did you resolve it?
16) Difference between green thread and native thread in Java?
17) Difference between thread and process?
18) What is context switching in multi-threading?
19) Difference between deadlock and livelock, deadlock and starvation?
20) What thread-scheduling algorithm is used in Java?
21) What is thread-scheduler in Java?
22) How do you handle un-handled exception in thread?
23) What is thread-group, why its advised not to use thread-group in Java?
24) Why Executor framework is better than creating and managing thread by application ?
25) Difference between Executor and Executors in Java?
26) How to find which thread is taking maximum cpu in windows and Linux server?
27) difference between final, finally and finalize in Java?
28) how do you design another programming language which can run like Java?
29) when to use abstract class over interface in Java?
30) how does lambda expression of Java 8 was implemented?
31) how does generics in Java implemented internally?
32) What is apect oriented programming and describe the way it is used in the Spring framework.
Fun using HTML5 canvas and Pixi.js
2015-08-21 18:09:51
While learning about HTML5 canvas, I've written a small icon/sprite editor in javascript.
It can also render sprite as tiles using Pixi.js framework.
http://www.nicolasmy.com/test/test_canvas.html
It can also render sprite as tiles using Pixi.js framework.
http://www.nicolasmy.com/test/test_canvas.html
Computer generated 2D shapes
2015-07-03 00:18:21
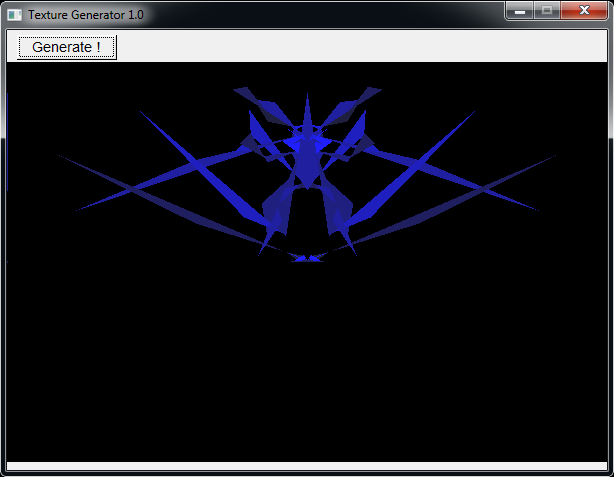
In order to create original game assets for a 2D shooter game, I've written an algorithm that generate random insect-like shapes.
It starts by drawing a triangle along a vertical symetrical axis, then triangles are added randomly under the constraint that they must be connected by an edge to a formerly added triangle.
Eventually the generated image is mirrored along the vertical axis.
Half-Life 2 : Oculus Rift, PS Move, Navigation Controller, Sharp Shooter
2015-05-15 21:53:41
This is merely a proof of concept : beeing able to play Half-Lige 2 with Oculus Rift. Aiming with the PS Move and moving using the Navigation controller.
I thought that the idea of using the Playstation Move with the Sharp Shooter accessory used as a pointing device, was a cool idea.
I've coded a quick and dirty hack that basically traps PS Move orienation changes and convert it into mouse motion.
It is essentially based on this framework to make the PS Move work on PC:
https://code.google.com/p/moveframework/
Requirements :
1. Install Eye Camera driver :
https://codelaboratories.com/products/eye/driver/
2. Install MotionInJoy driver (for PS3 bluetooth devices support)
3. Pair the PS Move and Navigation controller with the PC
Navigation controller has to be configured as PS2 controller
4. Use the Calibration tool provided by "moveframework" and make sure both Move and Navigation Controller are recognised.
5. Launch Halif-Life 2 with VR Support and gamepad support enabled in menu.
6. Start a game.
7. Switch to Windows desktop and launch my "mouse emulator"
8. Get back to the game and play.
NB: I still have to make the piece of software I've made available
Codingame : The labyrinth
2015-05-07 16:19:15
Another exercise that I haven't managed to complete : one has to crawl through a labyrinth, find a command point and get to the exit before the count down.
Progamatically speaking this is a classic backtracking exercise where we explore the maze in one direction until we reached a dead end, then try another direction, marking all visited areas so not to crawl to same area two times.
All the directions taken will then be stored to a stack and the stack will be played backward to get to our starting point after having activated the countdown in the maze.
Having implemented this behaviour properly will allow you to pass about half of the unit-tests.
For the others tests, one has to take elements :
* The countdown delay only allows for the optimal path to be taken.
* Multiple paths can exist between the switch and the exit point through the maze.
There's no way to cut it, one has to compute the optimal path between switch and maze exit. The easiest way to do so is to compute the distance map from the switch (ie : a map containing an integer value representing the distance from the current tile to the switch), this is done simply by crawling recursively in all four direction, stopping on non-reachable squares or where the computed distance on the square is already lower than the current computed distance.
Then by building the path from the starting point, looking for the neareast tile that lowers our distance, we can build our optimal path.
The second point is solved by not going straight to the switch but computing the distance from the switch to the exit and make sure that our current optimal path allows to reach the exit within the countdown. If not, then continue exploring the maze until such an optimal path is discovered, then get back to switch...
Only by implementing these additionnals behaviours, can the problem be solved to 100%.
Progamatically speaking this is a classic backtracking exercise where we explore the maze in one direction until we reached a dead end, then try another direction, marking all visited areas so not to crawl to same area two times.
All the directions taken will then be stored to a stack and the stack will be played backward to get to our starting point after having activated the countdown in the maze.
Having implemented this behaviour properly will allow you to pass about half of the unit-tests.
For the others tests, one has to take elements :
* The countdown delay only allows for the optimal path to be taken.
* Multiple paths can exist between the switch and the exit point through the maze.
There's no way to cut it, one has to compute the optimal path between switch and maze exit. The easiest way to do so is to compute the distance map from the switch (ie : a map containing an integer value representing the distance from the current tile to the switch), this is done simply by crawling recursively in all four direction, stopping on non-reachable squares or where the computed distance on the square is already lower than the current computed distance.
Then by building the path from the starting point, looking for the neareast tile that lowers our distance, we can build our optimal path.
The second point is solved by not going straight to the switch but computing the distance from the switch to the exit and make sure that our current optimal path allows to reach the exit within the countdown. If not, then continue exploring the maze until such an optimal path is discovered, then get back to switch...
Only by implementing these additionnals behaviours, can the problem be solved to 100%.
Coding game 25.04.2015 : There is no spoon
2015-04-30 17:52:31
http://www.codingame.com/leaderboards/challenge/there-is-no-spoon/1290383d2bd50490e590b55035815b3c1d65121
I've attended this challenge and although I've reached a not too shabby ranking of 167# out of 1628, I remain unsatisfied by my second exercise perfomance managing only to pass 54% of all unit tests.
This is a classic backtracking exercise on an oriented graph where one has to link node to each other depending on node valuation.
There was elements that would largely simplify this exercise :
1. Graph is oriented and link can only be made to the closest right neighbour or the closest bottom neighbour.
2. Only up to 2 links can connect two nodes.
=> For each nodes, the only cases are (link to right / link to bottom)
0/0, 1/0, 2/0, 2/1, 2/2, 1/2, 0/2, 0/1, 1/1
That's 9 possibilities per node but as it is incremental node valuation should match the amount of link.
The simplest solution that I think of is to brute force all available possibility for each node in a recursive manner.
3. There are 2 additionnals conditions :
* No link should cross one another
* Graph must be entirely connected
At first these conditions seems hard to enforce, but by looking closely it's not that hard to implement.
The first one can be checked when adding a right link : make sure that no vertical link crosses the horizontal link we are adding. Goin*g downward already ensured that no vertical link can cross an already created horizontal link.
The second condition is enforced by removing solutions that are not fully connected graphs. This seems expensive if one has to verify that every node is connected to every other node. There is a much simpler way : take a node, browse through all the connected neighbours (right and bottom but also top and left) and mark them as browsed. After having marked all reachable nodes, look for unmarked nodes => if any then our graph is not fully connected.
I've reworked on my solution and finally reached 100% for the second exercise.
I've attended this challenge and although I've reached a not too shabby ranking of 167# out of 1628, I remain unsatisfied by my second exercise perfomance managing only to pass 54% of all unit tests.
This is a classic backtracking exercise on an oriented graph where one has to link node to each other depending on node valuation.
There was elements that would largely simplify this exercise :
1. Graph is oriented and link can only be made to the closest right neighbour or the closest bottom neighbour.
2. Only up to 2 links can connect two nodes.
=> For each nodes, the only cases are (link to right / link to bottom)
0/0, 1/0, 2/0, 2/1, 2/2, 1/2, 0/2, 0/1, 1/1
That's 9 possibilities per node but as it is incremental node valuation should match the amount of link.
The simplest solution that I think of is to brute force all available possibility for each node in a recursive manner.
3. There are 2 additionnals conditions :
* No link should cross one another
* Graph must be entirely connected
At first these conditions seems hard to enforce, but by looking closely it's not that hard to implement.
The first one can be checked when adding a right link : make sure that no vertical link crosses the horizontal link we are adding. Goin*g downward already ensured that no vertical link can cross an already created horizontal link.
The second condition is enforced by removing solutions that are not fully connected graphs. This seems expensive if one has to verify that every node is connected to every other node. There is a much simpler way : take a node, browse through all the connected neighbours (right and bottom but also top and left) and mark them as browsed. After having marked all reachable nodes, look for unmarked nodes => if any then our graph is not fully connected.
I've reworked on my solution and finally reached 100% for the second exercise.
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int getRight(int x,int y,int width,int height,char * grid) {
for (int i = x + 1;i < width;i++) {
if ((grid[i+y*width] >= '0')&&(grid[i+y*width] <= '8')){
return i;
}
}
return -1;
}
int getBottom(int x,int y,int width,int height,char * grid) {
for (int j = y + 1;j < height;j++) {
if ((grid[x+j*width] >= '0')&&(grid[x+j*width] <= '8')){
return j;
}
}
return -1;
}
typedef struct {
int xr;
int yr;
int xb;
int yb;
int counter;
int mark;
int lr;
int lb;
} t_n;
t_n getNmap(t_n * nmap, int width,int height, int x, int y) {
return nmap[x+y*width];
}
int addLinkR(int i, int j, t_n * nmap, int width,int height);
int addLinkL(int i, int j, t_n * nmap, int width,int height);
int apply_ope(t_n * nmap,int width,int height, int x, int y,int ope) {
switch (ope) {
case 0 : // 0/0
if (getNmap(nmap,width,height,x,y).counter == 0) {
return 1;
} else {
return 0;
}
case 1 : // 0/1
if ((getNmap(nmap,width,height,x,y).counter == 1)&&addLinkR(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
case 2 : // 0/2
if ((getNmap(nmap,width,height,x,y).counter == 2)&&addLinkR(x, y, nmap, width, height)&&addLinkR(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
case 3 :// 1/1
if ((getNmap(nmap,width,height,x,y).counter == 2)&&addLinkR(x, y, nmap, width, height)&&addLinkL(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
case 4 :// 1/2
if ((getNmap(nmap,width,height,x,y).counter == 3)&&addLinkR(x, y, nmap, width, height)&&addLinkR(x, y, nmap, width, height)&&addLinkL(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
case 5 :// 2/2
if ((getNmap(nmap,width,height,x,y).counter == 4)&&addLinkR(x, y, nmap, width, height)&&addLinkR(x, y, nmap, width, height)&&addLinkL(x, y, nmap, width, height)&&addLinkL(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
case 6 :// 2/1
if ((getNmap(nmap,width,height,x,y).counter == 3)&&addLinkR(x, y, nmap, width, height)&&addLinkL(x, y, nmap, width, height)&&addLinkL(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
case 7 :// 2/0
if ((getNmap(nmap,width,height,x,y).counter == 2)&&addLinkL(x, y, nmap, width, height)&&addLinkL(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
case 8 :// 1/0
if ((getNmap(nmap,width,height,x,y).counter == 1)&&addLinkL(x, y, nmap, width, height)) {
return 1;
} else {
return 0;
}
default :
return 0;
}
}
int checkOverlapR(t_n * nmap, int width,int height,int x,int y,int x2, int y2) {
for (int i = 0;i < x+y*width;i++) {
if (nmap[i].lb > 0
&& x < (i%width)
&& x2 > (i%width)
&& y > (i/width) && y < nmap[i].yb) {
return 1;
}
}
return 0;
}
t_n * clone_nmap(t_n * nmap, int width,int height){
t_n * nmapd = (t_n*)malloc(sizeof(t_n)*width*height);
if (nmapd == 0) {
puts("clone_nmap : out of memory !\n");
}
memcpy(nmapd,nmap,sizeof(t_n)*width*height);
return nmapd;
}
void mark_cell(t_n * nmap,int width,int height, int x,int y) {
if (nmap[x+y*width].mark == 1) {
return;
}
nmap[x+y*width].mark = 1;
if ((nmap[x+y*width].xb != -1)&&(nmap[x+y*width].lb > 0)) {
mark_cell(nmap,width,height,nmap[x+y*width].xb,nmap[x+y*width].yb);
}
if ((nmap[x+y*width].xr != -1)&&(nmap[x+y*width].lr > 0)) {
mark_cell(nmap,width,height,nmap[x+y*width].xr,nmap[x+y*width].yr);
}
for (int i = 0;i < x+y*width;i++) {
if (((nmap[i].xb == x)&&(nmap[i].yb == y)&&(nmap[i].lb > 0))||((nmap[i].xr == x)&&(nmap[i].yr == y)&&(nmap[i].lr > 0))) {
mark_cell(nmap,width,height,i%width,i/width);
}
}
}
void mark_connected(t_n * nmap, int width,int height) {
int start = 0;
for (int i = 0;i < width*height;i++) {
if (nmap[i].mark != -1) {
start = i;
break;
}
}
mark_cell(nmap, width, height, start%width,start/width);
}
int check_connected(t_n * nmap, int width,int height) {
for (int i = 0;i < width*height;i++) {
if (nmap[i].mark != -1) {
nmap[i].mark = 0;
}
}
mark_connected(nmap,width,height);
for (int i = 0;i < width*height;i++) {
if (nmap[i].mark == 0) {
return 0;
}
}
return 1;
}
void browse_node(t_n * nmap,int pos, int width,int height) {
if (pos == (width*height-1)&&checkNmap(nmap,width,height)){
if (check_connected(nmap,width,height)) {
displayNmap(nmap,width,height);
exit(0);
} else {
return;
}
}
for (int j = 0;j < 9;j++) {
t_n * nmaptmp = clone_nmap(nmap,width,height);
if (apply_ope(nmaptmp,width,height, pos%width, pos/width,j)) {
browse_node(nmaptmp,pos+1,width,height);
}
free(nmaptmp);
}
}
int addLinkR(int i, int j, t_n * nmap, int width,int height) {
t_n current= getNmap(nmap,width,height,i,j);
if ((current.counter > 0)&&(current.lr < 2)&&(current.xr!=-1)&&(current.yr!=-1)) {
if ((getNmap(nmap,width,height,current.xr,current.yr).counter > 0) &&(!checkOverlapR(nmap,width,height,i,j,current.xr, current.yr))) {
nmap[i+j*width].counter--;
nmap[i+j*width].lr++;
nmap[current.xr+current.yr*width].counter--;;
return 1;
}
}
return 0;
}
int addLinkL(int i, int j, t_n * nmap, int width,int height) {
t_n current= getNmap(nmap,width,height,i,j);
if ((current.counter > 0)&&(current.lb < 2)&&(current.xb!=-1)&&(current.yb!=-1)) {
if (getNmap(nmap,width,height,current.xb,current.yb).counter > 0) {
nmap[i+j*width].counter--;
nmap[i+j*width].lb++;
nmap[current.xb+current.yb*width].counter--;
return 1;
}
}
return 0;
}
int checkNmap(t_n * nmap, int width,int height) {
for (int i = 0;i < width * height;i++) {
if (nmap[i].counter > 0){
return 0;
}
}
return 1;
}
void displayNmap(t_n * nmap, int width,int height) {
for (int i = 0;i < width;i++) {
for (int j = 0;j < height;j++) {
t_n current = getNmap(nmap,width,height,i,j);
if (current.lr > 0) {
printf("%d %d %d %d %d\n",i,j,current.xr,current.yr,current.lr);
}
if (current.lb > 0) {
printf("%d %d %d %d %d\n",i,j,current.xb,current.yb,current.lb);
}
}
}
}
int main()
{
int width; // the number of cells on the X axis
scanf("%d", &width); fgetc(stdin);
int height; // the number of cells on the Y axis
scanf("%d", &height); fgetc(stdin);
char * grid = (char*)malloc(sizeof(char)*width*height);
char * line = (char*)malloc(sizeof(char)*(width+1));
t_n * nmap = (t_n*)malloc(sizeof(t_n)*width*height);
for (int i = 0; i < height; i++) {
fgets(line,31,stdin); // width characters, each either 0 or .
for (int j = 0;j < width;j++) {
grid[j+i*width] = line[j];
}
}
fprintf(stderr,"width=%d\n",width);
fprintf(stderr,"height=%d\n",height);
for (int i = 0; i < height; i++) {
fprintf(stderr,"[");
for (int j = 0;j < width;j++) {
fprintf(stderr,"%c",grid[j+i*width]);
}
fprintf(stderr,"]\n");
}
for (int i = 0; i < width; i++) {
for (int j = 0;j < height;j++) {
nmap[i+j*width].lb = 0;
nmap[i+j*width].lr = 0;
nmap[i+j*width].counter = 0;
nmap[i+j*width].mark = -1;
nmap[i+j*width].xr = -1;
nmap[i+j*width].yr = -1;
nmap[i+j*width].xb = -1;
nmap[i+j*width].yb = -1;
if ((grid[i+j*width] >= '0')&&(grid[i+j*width] <= '8')) {
int xr = getRight(i,j,width,height,grid);
int yr = xr == -1 ? -1 : j;
int yb = getBottom(i,j,width,height,grid);
int xb = yb == -1 ? -1 : i;
nmap[i+j*width].mark = 0;
nmap[i+j*width].xr = xr;
nmap[i+j*width].yr = yr;
nmap[i+j*width].xb = xb;
nmap[i+j*width].yb = yb;
nmap[i+j*width].lb = 0;
nmap[i+j*width].lr = 0;
char s[2];
s[0] = grid[i+j*width];
s[1] = 0;
nmap[i+j*width].counter = atoi(s);
}
}
}
browse_node(nmap,0,width,height);
free(grid);
free(line);
free(nmap);
fprintf(stderr,"exit !\n");
}